Finding out the needy one from Tweets : An analysis using #kerelafloods
Natural disasters are very difficult to predict and when they happen it’s very difficult for the government and different aid agencies to get the real time information about the disaster affecting people or properties. To save the life and properties first step to know where it happens and what is the current scenario of that place. To get this information social media plays a key role. In this article, we explore a detailed overview on Kerala flood situation which happened in late July 2018, severe flooding affected Kerala very badly. In this article, we proposed a system to detect real-time help needed to people based on different tweets related to Kerala flood. This article provided a complete detailed overview on the situation in Kerala and collects needed information through tweets as Twitter is one of the best ways of spreading awareness about the worsening situation in Kerala. To alleviate this problem, tweets, which are largely available,can be exploited to extract the required data from Twitter.
Background Study
Time to time technology helps people who are suffering from natural disasters. During the Haiti earthquake 2010, another SMS system designed for communication in between disaster affected people and aid agencies named as Trilogy Emergency Relief Application (TERA). During the Nepal’s earthquake, NASA launched a device called Finding Individuals for Disaster and Emergency Response (FINDER) to detect humans who are buried under buildings, roads etc. This device is the size of a small briefcase which is a heartbeat detection radar designed to detect victims buried in rubble.
Proposed Research
In this project, the tweets of Kerala floods were taken as an input to analyze the different scenarios to help people in real-time. We have extracted the hashtags from tweets and applied clustering algorithms (e. g KMeans) to group similar messages and information. The analysis is restricted to 15000 tweets extracted by looking for the hashtag #keralaflood. Topic analysis of preprocessed tweets is done using Latent Dirichlet Allocation. In a further step, we did the preprocessing of data by removing stopwords, URLs, punctuation, tokenization, stemming and hashtags were extracted from tweets with bigram using regular expressions. The hashtags, capture the subject of tweet and prefixed by ’#’ character. The hashtags may carry sentiments or emotions (#sarcasm), actions (#accommodate), climate (#rain) and many more. We converted the hashtags from text to its vector representation using the TF-IDF approach, such that it could be utilized in KMeans clustering and Topic modelling algorithms. After preprocessing, we have counted, which hashtag was used most frequently, counted its frequency and plotted using matplotlib.
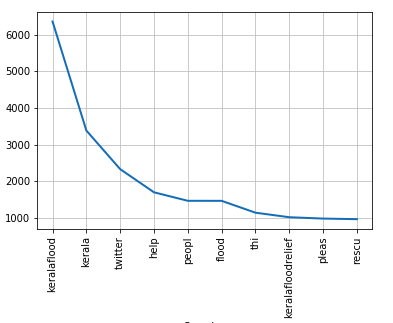
We have calculated cosine similarity among the tweets. Cosine similarity is a measure of similarity between two non-zero vectors of an inner product space that measures the cosine of the angle between them. Cosine similarity helps in measuring cohesion within clusters. We used K-Means clustering algorithm to group tweets into chosen number (say, here 5) of groups as shown in Table-1
| Cluster | Words | Frequency |
|---|---|---|
| 0 | keralaflood, twitter, kerala, rescue, flood | 115 |
| 1 | Help, donate, people, please, need | 3925 |
| 2 | chiefminister, minister, relief, fund, crore | 72 |
| 3 | children, feet-long-bridge, rescue, malampuzha, senior-citizen | 257 |
| 4 | twitterkeralaflood, status, keralafloodrelief, keralaflood, kerala | 1824 |
Topic modeling is a very important step for text-processing as it deduces the theme of texts (in this case tweets). A topic model is a type of statistical model for discovering the abstract ”topics” that occur in a collection of documents. LDA was implemented to identify the topic of the tweets as shown in Table-2:
| Topic | Words |
|---|---|
| 0 | keralaflood, kerala, nation, need, flood, relief |
| 1 | keralaflood, twitter, family, rescue, flood, people |
| 2 | keralaflood, twitter, kerala, rescue, water, operation |
| 3 | keralaflood, road, twitter, ernakulam, near, please |
| 4 | keralaflood, twitter, train, kerala, govern, keralafloodrelief |
Conclusions
It is clear from the analysis that how powerful social media is and it can be used very widely to help mankind and other species. Social media can be harnessed to great effect in times of crisis. This system will surely help the Government agencies like NDRF, CRPF , Home Ministry and other aid relief agencies in collecting different data to develop analytics capabilities focused on mining Twitter for real-time updates to take meaningful action during the crisis and disaster like flood in Kerala. Disasters may strike at any time, While prevention from them may not be possible, but it is advisable and better to be prepared for unfortunate eventualities.
Project repository - GithubReferences
1. N. Saharia, “Detecting emotion from short messages on nepal earthquake,” in Speech Technology and Human-Computer Dia- logue (SpeD), 2015 International Conference on. IEEE, 2015, pp. 1–5.
2. S. Kedar, S. Owen, C. Jones, A. Donnelan, M. Glasscoe, and R. Duren, “Select technologies and capabilities to improve earth- quake resiliency in california,” 2016.

Rahul Ranjan (Author)
I am a final year undergrad at IIIT Manipur having keen interest in technology, research, reading and writing.
Email - rahul@iiitmanipur.ac.in
Rajiv Ranjan
Thank you!! Awesome artciles and provides a practical approach for application of Machine learning in real-life dataset.
Reply